
Better sharing on social media platforms with Angular Universal
Posted on
Angular Universal - Advanced techniques series
This article is part of a growing series around advanced techniques in Angular with Universal. If you get excited about this article be sure to check the others!
- Better sharing on social media platforms with Angular Universal
- Outputting JSON-LD with Angular Universal
- Creating a simple memory cache for your Angular Universal website or application
- Angular v9 & Universal: SSR and prerendering out of the box!
Target audience
This article and guide on better sharing on social media platforms with Angular Universal is targeted to developers that have at least a basic understanding of Angular and might already have an Angular Universal implementation up and running. We are going to describe some high-level ideas and concepts, different tools and Angular services that will enable better social sharing for platforms like Facebook, Twitter and LinkedIn.
Angular Universal and SEO problems with SPAs
It’s not a new concept, running Angular on the server with Universal. The first version of this website was built with Angular v2 and Universal concepts back in November 2016. The tooling around it has grown a lot since then and my website evolved together with those tooling updates.
It’s much easier to build an Angular universal website or app today because it’s completely documented and there are a lot of example projects available. Angular CLI also gives us the tools to add this functionality automatically by using simple commands.
The fact that SPAs in general have big problems with indexing and social sharing has been a topic for many discussions, and for many years, ever-since the first JS applications were build. Different approaches have been considered and one of them, like prerendering the application with a headless browser like PhantomJS or Puppeteer and serving different content for different consumers, bots vs real visitors, can be categorized as black hat SEO.
Indexing capabilities of SPAs by search engines
When you generate an Angular application via the angular-cli a polyfills.ts file gets generated. It includes the following content:
polyfills.ts
/** IE9, IE10, IE11, and Chrome <55 requires all of the following polyfills.
* This also includes Android Emulators with older versions of Chrome
* and Google Search/Googlebot
*/
This means that our Angular app has support for the Google Search / Googlebot, even without SSR, if we include those specific polyfills. It does not mention any other search engines. The other typical search engines, like Bing, Yahoo, DuckDuckGo, etc all have problems parsing JavaScript heavy websites, like SPAs or applications that use frameworks like for example jQuery.
Update (May 2019): The Google bot / crawler is now up-to-date with the latest Chromium and will update regularly. You can read more about this update on the Google Webmasters Blog.
The overview below gives us a good idea which search engines are capable of indexing JavaScript heavy applications, build with different frameworks and libraries.
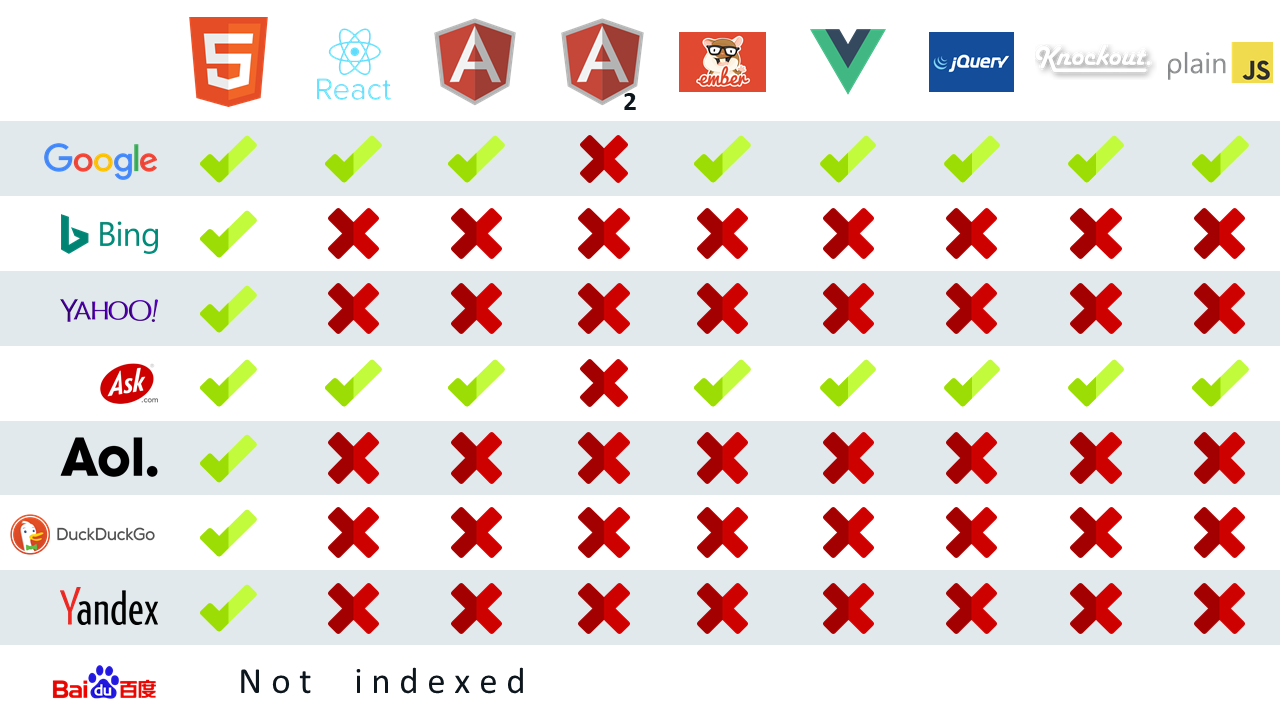
All credits for this overview go to Bartosz Góralewiczm, see also blogpost linked below
If you want to read more about this topic, I suggest reading https://moz.com/blog/search-engines-ready-for-javascript-crawling. The blogpost is a little bit outdated as the crawlers have most likely evolved in their capabilities, like for example the ability of the Googlebot to parse Angular v2+ applications. The general problem remains: Search engines are, in general, not very capable of rendering JavaScript while indexing.
The 2nd wave of indexing
It would be wrong stating that SPAs are not being indexed. Google does an extra effort in the 2nd wave of indexing, where parsing of JS-heavy applications is done better. More information about this specific topic can be found here.
Google, Bing and others are not the only search engines
Everything that is described above is also true for other crawlers, like those of Facebook, Twitter and LinkedIn, just to name a few of the social media platforms I consider to be important for my cases. These can also be considered search engines, because they parse and cache the content of your website or application when their users share your content.
And just like the other typical search engines, most of them, if not all, are not capable of parsing JavaScript and only rely on the statically generated HTML.
How do social media platforms crawl your page?
Social media platforms use your statically generated HTML to show a preview when sharing one of your pages on their feed. Therefor they parse the title and meta tags that can be found in the <head> tag.
static-generated.html
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Sam Vloeberghs - Freelance Webdeveloper & Software Engineer</title>
<meta name="description" content="Hi there! 👋 Thank you for visiting my website!">
<meta name="author" content="Sam Vloeberghs">
</head>
...This seems easy, but it's not that easy to get it right. Because all the different social media platforms expect other meta tags for rendering their previews. They don't even use the same attribute to identify the correct meta tags. Some use the name attribute and others use the property attribute. It means you'll have to support around 15 different meta tags to get the basics like title, image, description and author right (for Facebook, LinkedIn and Twitter).
All of the discussed social media platforms provide us with tools to validate our pages or posts before sharing them. Some platforms, like Facebook and LinkedIn cache all the shared content, so these tools also allow us to invalidate cached content. Super handy if you have already shared your page before, or if you want to invalidate the cache of a set of pages in one go.
To get Facebook to show your content correctly you need to implement the following basic meta tags. Please note that Facebook uses the property attribute to define the type of meta value and that those types are always prefixed with og:, which is the prefix for the open-graph protocol.
static-generated-facebook.html
<head>
<meta property="og:title" content="Sam Vloeberghs - Freelance Webdeveloper & Software Engineer">
<meta property="og:description" content="Hi there! 👋 Thank you for visiting my website!">
<meta property="og:url" content="https://samvloeberghs.be/">
<meta property="og:image" content="/assets/share_img.png">
<meta property="og:image:alt" content="Sam Vloeberghs - Freelance Webdeveloper & Software Engineer">
<meta property="og:image:height" content="xxx">
<meta property="og:image:width" content="xxx">
</head>The open-graph protocol allows for a lot more meta tags to be defined. Especially Facebook supports a lot more, like video. Check the documentation for Facebook sharing to learn more.
Facebook Sharing Debugger
Validating a preview of your post on Facebook can be done via https://developers.facebook.com/tools/debug/sharing. Facebook also provides a way to invalidate a batch of pages, which can also be done programmaticaly via their API.
To get your post to show correctly on LinkedIn you need to implement the following basic meta tags. Please note that LinkedIn also uses the og: prefixes, but not for all values, like the author meta tag.
static-generated-linkedin.html
<head>
<meta property="og:title" content="Sam Vloeberghs - Freelance Webdeveloper & Software Engineer">
<meta property="og:type" content="website">
<meta property="og:image" content="/assets/share/home.png">
<meta property="og:description" content="Hi there! 👋 Thank you for visiting my website!">
<meta name="author" content="Sam Vloeberghs">
</head>LinkedIn Post Inspector
Validating a preview of your post or website and refreshing the cache on LinkedIn can be done via https://www.linkedin.com/post-inspector/.
The only thing I'm still not sure about is which meta property or name they use to correctly read out the "Publish date". I have asked the question to their support and I'm still waiting for an answer. And sadly there is little to no documentation to be found on this subject.
Update: I did some trial-and-error testing and it seems that the meta tag <meta name="published_date" content="2019-02-24T11:00:00.000Z"> does the trick.
To get your post to show correctly on Twitter as a card you need to implement the following meta tags. Please note that, compared to Facebook and LinkedIn, Twitter uses the name attribute to define the type of meta value and that those types are always prefixed with twitter:.
static-generated-twitter.html
<head>
<meta name="twitter:card" content="summary_large_image">
<meta name="twitter:title" content="Sam Vloeberghs - Freelance Webdeveloper & Software Engineer">
<meta name="twitter:description" content="Hi there! 👋 Thank you for visiting my website!">
<meta name="twitter:image" content="https:///samvloeberghs.be/assets/share/home.png">
<meta name="twitter:image:alt" content="Sam Vloeberghs - Freelance Webdeveloper & Software Engineer">
<meta name="twitter:site" content="@samvloeberghs">
<meta name="twitter:creator" content="@samvloeberghs">
</head>Twitter Card Validator
Validating the preview of your post on Twitter can be done via https://cards-dev.twitter.com/validator.
Important: The value of twitter:image must be a fully-qualified complete and absolute URL, not a partial/relative one, or the Twitter crawler will be unable to find and display the image.
Using the Meta and Title services in Angular
To achieve all this, the only 2 services we need to use are the Title and Meta service. We use them to dynamically update the title of a webpage and for setting the required meta tags described before.
Using the router we can attach metadata that needs to be coupled to our routes. If we want to set the title for a dynamic page, like for example a blogpost, we need to get the data first and then call the same services to update the meta and title tags. As you can see in the example below, for the about page, we've configured these values and attached them to the route.
about-routing.module.ts
RouterModule.forChild([{
path: '',
component: AboutComponent,
data: {
seo: {
title: `About Sam - ${environment.seo.title}`,
description: `I'm a 30 year old software engineer living in Belgium.`,
shareImg: '/assets/share/about.png',
}
}
}])Using a service we can subscribe to route changes to extract this data and update our title and meta tags.
route-helper.service.ts
@Injectable({
providedIn: 'root',
})
export class RouteHelper {
constructor(
private readonly router: Router,
private readonly activatedRoute: ActivatedRoute,
private readonly seoSocialShareService: SeoSocialShareService
) {
this.setupRouting();
}
private setupRouting() {
this.router.events.pipe(
filter(event => event instanceof NavigationEnd),
map(() => this.activatedRoute),
map(route => {
while (route.firstChild) {
route = route.firstChild;
}
return route;
}),
filter(route => route.outlet === 'primary')
).subscribe((route: ActivatedRoute) => {
const seo = route.snapshot.data['seo'];
// set your meta tags & title here
this.seoSocialShareService.setData(seo);
});
}
}As explained above, all our social platforms expect other meta tags. Therefore it's best to create a SEO wrapper service, that injects the Meta Service and Title service from Angular. As an example, I will only implement the method to update the title value on our pages. If you want to see the full example, have a look at the full implementation of my SeoService.
ngx-seo/seo-social-share.service.ts
@Injectable({
providedIn: 'root',
})
export class SeoSocialShareService {
constructor(
private readonly metaService: Meta,
private readonly titleService: Title
) {
}
setData(data: SeoSocialShareData) {
this.setTitle(data.title);
... // set all other meta tags
}
private setTitle(title: string = '') {
this.titleService.setTitle(title);
if (title && title.length) {
this.metaService.updateTag({name: 'twitter:title', content: title});
this.metaService.updateTag({name: 'twitter:image:alt', content: title});
this.metaService.updateTag({property: 'og:image:alt', content: title});
this.metaService.updateTag({property: 'og:title', content: title});
this.metaService.updateTag({name: 'title', content: title});
} else {
this.metaService.removeTag(`name='twitter:title'`);
this.metaService.removeTag(`name='twitter:image:alt'`);
this.metaService.removeTag(`property='og:image:alt'`);
this.metaService.removeTag(`property='og:title'`);
this.metaService.removeTag(`name='title'`);
}
}
}Watch out for over-optimization
When generating static pages server side you might consider optimizing the rendered HTML as well. Tools like HTMLMinifier take out all the bloat from your HTML, to keep the bare minimum that the browser needs to be capable of rendering it.
But be careful. Browsers like Chrome, Firefox and others are able to parse your minified HTML, as they are very forgiving and fix errors for us. But parsers that rely heavily on structured HTML, like the ones the social platforms use, might not be able to parse it correctly and get out the information they need.
A simple example
The following HTMLminifier options remove all the stuff the browser does not need to correctly show your page:
too-much-minify-options.ts
const tooMuchHtmlMinifyOptions = {
removeComments: true,
removeCommentsFromCDATA: true,
collapseWhitespace: true,
collapseBooleanAttributes: true,
removeRedundantAttributes: true,
useShortDoctype: true,
removeEmptyAttributes: true,
minifyCSS: true,
removeAttributeQuotes: true,
removeOptionalTags: true
};
const minify = require('html-minifier').minify;
const minifiedHtml = minify(html, minifyOptions);Let's process the following HTML:
too-much-minify-options-input.html
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta property="og:title" content="Sam Vloeberghs - Freelance Webdeveloper & Software Engineer">
...results in
too-much-minify-options-output.html
<!doctype html><html lang=en><meta charset=utf-8><meta property=og:title content="Sam Vloeberghs - Freelance Webdeveloper & Software Engineer">This is too much optimization for the LinkedIn Post Inspector. If you look closely, you'll notice that the optional <head> tag was removed and that the quotes around simple attribute values, with a single non-spaced value, were removed as well. To be able to minify the HTML and keep the LinkedIn Post Inspector happy we need to change our configuration a little bit. We want to keep the attribute quotes and optional tags:
good-minify-options.ts
const goodHtmlMinifyOptions = {
…
removeAttributeQuotes: false,
removeOptionalTags: false
};Now let's rerun the minifier again with the same HTML as mentioned above and see what the final result looks like:
good-minify-options-output.html
<!doctype html><html lang="en"><head><meta charset="utf-8"><meta property="og:title" content="Sam Vloeberghs - Freelance Webdeveloper & Software Engineer">We are keeping the <head> tag and the attribute quotes. And now the LinkedIn Post Inspector is happy 😃.
Conclusion
Not all search engines behave the same way. Not only Google, Bing etc. can be categorized as search engines but we have to think about Social platforms like Facebook, Twitter and LinkedIn, that also crawl and cache external content. Each crawler behaves in a different way and most of them are not capable of parsing JavaScript heavy applications.
This means we have to adjust and configure our applications very specifically for the different crawlers of the social platforms we want to support. By using Angular Universal, we are able to generate a static version of your application on the server and output static HTML. When minifying this static HTML we need to be careful and keep our HTML as strict and structured as possible.
Further reading
Special thanks to
for reviewing this post and providing valuable and much-appreciated feedback!
Contents
- Introduction
- Target audience
- Angular Universal and SEO problems with SPAs
- Indexing capabilities of SPAs by search engines
- The 2nd wave of indexing
- Google, Bing and others are not the only search engines
- How do social media platforms crawl your page?
- Facebook Sharing Debugger
- LinkedIn Post Inspector
- Twitter Card Validator
- Using the Meta and Title services in Angular
- Watch out for over-optimization
- A simple example
- Conclusion
- Further reading
- Special thanks to
By reading this article I hope you can find a solution for your problem. If it still seems a little bit unclear, you can hire me for helping you solve your specific problem or use case. Sometimes even just a quick code review or second opinion can make a great difference.